In my two recent articles, "Mapping Java Objects to a Database with Castor-JDO" and "Cultivating your Relationship with Castor-JDO", I've presented Castor JDO, a framework for mapping Java objects to a relational database. The Castor project also houses another, very popular mapping framework, Castor XML, which is used to map Java objects to XML documents. In this article we'll look into how Castor XML could be yet another useful item in your toolbox.
Why would you want to use Castor XML as the bridge to an XML file when you have several other tools like JDOM, SAX, and dom4j that'll do the same thing? The answer is that Castor is able to elegantly map XML documents directly to instances of your own Java classes. In other words: if someone comes along with an XML document containing "customer data": name, address and so on, and you've got some Java classes that can hold name, addresses etc, then you'd normally be able to specify a mapping (through an XML mapping file) that would allow transformations from the XML document to your classes and back again, without having to make modifications to your Java code.
But Castor XML can do more than this. If you only have an XML-document, whose contents you would like to work with in your Java program, then Castor is also able to create the necessary Java classes for you.
I'll illustrate this by taking a deployment descriptor for a web application, and then let Castor create the Java code needed for processing it. The deployment descriptor file is most often named web.xml, and if you're running a web server (like Tomcat) on your computer, then go and search for this file, and you'll probably find several, since there's one for each application/project on your server.
In order for Castor to convert between XML documents and Java objects, it needs "mapping information" which can be obtained from several sources:
The first possibility alone is only an option in simple situations. Normally you'd need to tell Castor how XML-elements and Java-classes should be mapped, and this is done using a mapping file in XML-format.
A very small example: Assume that you have a class called demo.Person with instance variables called occupation and lastName, and an XML-document containing:
. . . <person occupation="programmer"> <lastname>Gosling</lastname> </person> . . . |
A Castor mapping file that will match this document to the Person class is this:
. . .
<class name="demo.Person">
<map-to xml="person"/>
<field name="occupation" type="string">
<bind-xml name="occupation" node="attribute"/>
</field>
<field name="lastName" type="string">
<bind-xml name="lastname" node="element"/>
</field>
</class>
. . .
|
The class- and field-elements refer to the Java class, and the map-to- and bind-xml-elements to the XML-document.
I won't go into details about how to construct the mapping file--there are several very good articles on the web giving examples on this, and I've listed some of the best in the resources section at the end of the article. Instead we'll start looking at the third mapping option using class descriptors.
If your starting point is the XML-document, and you don't have any Java classes yet to handle this document, then Castor has tools that can generate the classes. These classes will work without a mapping file, as we'll see shortly.
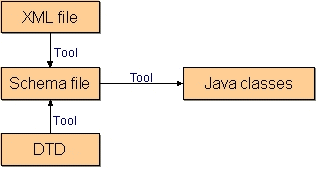
For Castor to create the Java classes it needs an XML Schema file. If you only have a DTD then Castor has a tool that'll convert a DTD to a Schema file. And if you have neither a Schema nor a DTD file but only an example of how your XML might look then Castor is still able to help you with another tool.
Figure 1. Castor conversion tools
By the way: a superior tool for making these kinds of conversions, and several others, is XMLSpy, but it has a price attached to it.
For the following examples I'll use a typical web application deployment descriptor. I've taken the web.xml file from Jakarta Struts' "blank application", which is part of the Struts download. It has this format:
Listing 1. web.xml for the Struts-blank application
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN"
"http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">
<web-app>
<!-- Standard Action Servlet Configuration (with debugging) -->
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>org.apache.struts.action.ActionServlet</servlet-class>
<init-param>
<param-name>config</param-name>
<param-value>/WEB-INF/struts-config.xml</param-value>
</init-param>
<init-param>
<param-name>debug</param-name>
<param-value>2</param-value>
</init-param>
<init-param>
<param-name>detail</param-name>
<param-value>2</param-value>
</init-param>
<load-on-startup>2</load-on-startup>
</servlet>
<!-- Standard Action Servlet Mapping -->
<servlet-mapping>
<servlet-name>action</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
<!-- The Usual Welcome File List -->
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
<!-- Struts Tag Library Descriptors -->
<taglib>
<taglib-uri>/tags/struts-bean</taglib-uri>
<taglib-location>/WEB-INF/struts-bean.tld</taglib-location>
</taglib>
. . . (several other taglibs follow) . . .
</web-app>
|
You'll see that the corresponding DTD is named at the top of the file, and you can find it in the struts.jar file if you're interested. It's not very well suited for our example, since the DTD is very large, and therefore will generate many, many classes.
Let's instead use the XML-to-Schema tool which is part of the Castor XML download. You use it from a DOS or UNIX shell prompt. Here's a Windows bat-file that sets up the tool:
Listing 2. Tool for converting an XML document to Schema
rem Syntax: XML2Schema "name-of-XML-file" "name-of-Schema-file" set classpath=castor-0.9.4.3.jar;xerces.jar java org.exolab.castor.xml.schema.util.XMLInstance2Schema %1 %2 |
Note, that I've placed a jar file containing an XML parser (Xerces) in the same directory as the Castor jar file. To convert the webapp descriptor file you enter:
XML2Schema web-struts-blank.xml web-struts-blank.xsd
The generated Schema file is not 100% correct, and it can't be, since the input file is only an example. Here's a figure made with XMLSpy, which shows the generated Schema structure:
Figure 2. The structure of the web.xml schema
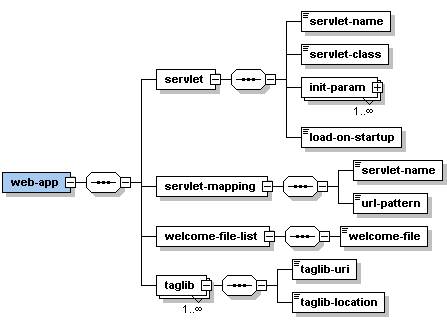
If you're familiar with the structure of web deployment descriptors you'll notice that the servlet and servlet-mapping elements should be made repeatable, and several elements should be made optional. With some basic knowledge about Schemas it's simple to fix this with any text editor, and here's a link to the final Schema file for web.xml and the XMLSpy picture of the structure .
We're now ready to convert the generated Schema to Java classes using Castor's Source Code Generator. Here's a Windows bat-file that invokes this tool:
Listing 3. Tool for converting a Schema to Java classes
rem Syntax: Schema2Java "name-of-Schema-file" "name-of-package" set classpath=castor-0.9.4.3.jar;xerces.jar java org.exolab.castor.builder.SourceGenerator -i %1 -package %2 %3 %4 %5 |
There are several parameters to this tool, which are documented at Castor's web site, and also in the Castor download (look in the doc-folder).
To get the classes in a directory called hansen.playground.webxml you issue this command:
Schema2Java web-struts-blank.xsd hansen.playground.webxml -types j2
The "-types j2" option is only used to force java.util.Collection to be used instead of java.util.Vector.
When you look in the hansen.playground.webxml folder, you'll find classes for the Schema elements seen in figure 2:
InitParam.java Servlet.java ServletMapping.java Taglib.java WebApp.java WelcomeFileList.java |
The main purpose of these classes is to act as beans that will hold the data from a web.xml file.
For each of the classes there's a corresponding "Descriptor" file. These files contain all the information needed to convert the data in a web.xml file into instances of the beans--and back again. A mapping file is therefore not needed. This sounds attractive, but you should note that we now have a very tight binding between the web-xml file (actually the Schema file) and the Java classes. We can't for example change the name of an instance variable in a bean without also making a change somewhere in the corresponding Descriptor class. And if we want to run the Code Generator again, we must be careful not to lose code we might have added to the beans. But assuming that we can live with these restrictions it's now a simple matter to read a web.xml file and create the corresponding objects.
The process of converting an XML document into Java objects is called "unmarshalling":
Listing 4. Test program for converting an XML document into Java objects
package hansen.playground.webxml;
import java.io.FileReader;
public class Test {
public static void main(String args[]) {
try {
FileReader in = new FileReader("web-struts-blank.xml");
WebApp webapp = WebApp.unmarshal(in);
in.close();
printWebXML(webapp);
} catch (Exception e) {
System.out.println(e);
}
}
public static void printWebXML(WebApp webapp) {
// Print the contents of the xml file
. . .
|
We use the unmarshall-method in the WebApp class--which corresponds to the root element in web.xml--to generate all the objects. A small print-method is used to show us the data. The complete program is here. When it is run it produces this output:
Listing 5. Output from test program
*** Data in web.xml file
Servlets:
Name/class: action/org.apache.struts.action.ActionServlet
Init parameters:
Name/value: config//WEB-INF/struts-config.xml
Name/value: debug/2
Name/value: detail/2
Load on startup: 2
Servlet Mappings:
Name/URL: action/*.do
Welcome File List:
Filename: index.jsp
Taglibs:
Uri/location: /tags/struts-bean//WEB-INF/struts-bean.tld
Uri/location: /tags/struts-html//WEB-INF/struts-html.tld
Uri/location: /tags/struts-logic//WEB-INF/struts-logic.tld
Uri/location: /tags/struts-nested//WEB-INF/struts-nested.tld
Uri/location: /tags/struts-tiles//WEB-INF/struts-tiles.tld
|
You may want to compare it with the web-struts-blank.xml file in figure 2 -- or view the file here.
If you look in the WebApp class you'll see that references to the "unbounded" elements like <servlet>, <servlet-mapping>, and <taglib> are implemented using ArrayList's, and for each there's a get-method that'll return an array of the appropriate class, for example for the <servlet> element:
. . . public hansen.playground.webxml.Servlet[] getServlet() . . . |
For simple Schema elements like <servlet-name> you'll find the usual get-method:
. . . public String getServletName() . . . |
It's just as simple to convert the objects back to an XML file. This is called "marshalling". Extending the test program from above we get:
. . .
printWebXML(webapp);
FileWriter out = new FileWriter("outdesc.xml");
webapp.marshal(out);
out.close();
. . .
|
The output is identical to the original web.xml file. If however you remove the class descriptor files from your classpath, you'll not get an identical result. Here's an extract from the generated file:
Listing 6. The generated web.xml file
<?xml version="1.0" encoding="UTF-8"?>
<web-app taglib-count="5" valid="true" servlet-mapping-count="1" servlet-count="1">
<servlet-mapping valid="true">
<servlet-name>action</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
<taglib valid="true">
<taglib-uri>/tags/struts-bean</taglib-uri>
<taglib-location>/WEB-INF/struts-bean.tld</taglib-location>
</taglib>
. . .
<welcome-file-list welcome-file-count="1">
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
<servlet load-on-startup="2" init-param-count="3" valid="true">
<servlet-name>action</servlet-name>
<init-param valid="true">
<param-name>config</param-name>
<param-value>/WEB-INF/struts-config.xml</param-value>
</init-param>
. . .
<servlet-class>org.apache.struts.action.ActionServlet</servlet-class>
</servlet>
</web-app>
|
Most of the information is correct, but "load-on-startup" is now an attribute, not an element, so Castor needs more information to get back to the original format. Instead of using class descriptors you can supply the information through a mapping file--the topic we'll look into in a minute.
To get indentation on the output you must set an option to Castor. See the Castor documentation.
If you prefer a looser coupling between your XML files and your Java classes you can tell the Source Generator to skip generation of the descriptor classes and also the marshalling methods. Use these parameters:
Schema2Java web-struts-blank.xsd hansen.playground.webxml2 -types j2 -nodesc -nomarshall
This time we'll only get the 6 beans generated. Since there are no marshal-methods in the beans any more, we'll have to modify our test program slightly:
Listing 7. A test program that uses the Unmarshaller and Marshaller classes
package hansen.playground.webxml;
import java.io.FileReader;
import java.io.FileWriter;
import org.exolab.castor.xml.Marshaller;
import org.exolab.castor.xml.Unmarshaller;
public class Test4 {
public static void main(String args[]) {
try {
FileReader in = new FileReader("web-struts-blank.xml");
//WebApp webapp = WebApp.unmarshal(in);
Unmarshaller unm = new Unmarshaller(WebApp.class);
WebApp webapp = (WebApp)unm.unmarshal(in);
in.close();
printWebXML(webapp);
FileWriter out = new FileWriter("outraw.xml");
//webapp.marshal(out);
Marshaller mars = new Marshaller(out);
mars.marshal(webapp);
out.close();
} catch (Exception e) {
System.out.println(e);
}
}
public static void printWebXML(WebApp webapp) {
. . .
|
If we run this test program, we observe that web-struts-blank.xml is still read correctly, but the output xml file is again not quite what we'd like. We need the mapping file to get a better result.
First of all Castor offers you yet another utility--this time for creating a mapping file. There's a short note about it in the Castor documentation. Here's a Windows bat-file for using it:
Listing 8. Tool for generating a mapping file
rem Syntax: mapping "input-class" "output-mapping-filename" set classpath=castor-0.9.4.3.jar;xerces.jar;. java org.exolab.castor.tools.MappingTool -i %1 -o %2 |
To get a mapping file for all the web.xml beans we enter:
mapping hansen.playground.webxml2.WebApp webapp.xml
Here's the generated mapping.file (webapp.xml) .
To use this mapping file we make a few changes to our test program:
Listing 9. A test program that uses a mapping file
package hansen.playground.webxml2;
import java.io.FileReader;
import java.io.FileWriter;
import org.exolab.castor.mapping.Mapping;
import org.exolab.castor.xml.Marshaller;
import org.exolab.castor.xml.Unmarshaller;
public class Test5 {
public static void main(String args[]) {
try {
Mapping mapping = new Mapping();
mapping.loadMapping("webapp.xml");
FileReader in = new FileReader("web-struts-blank.xml");
//WebApp webapp = WebApp.unmarshal(in);
Unmarshaller unm = new Unmarshaller(WebApp.class);
unm.setMapping(mapping);
WebApp webapp = (WebApp)unm.unmarshal(in);
in.close();
printWebXML(webapp);
FileWriter out = new FileWriter("outraw2.xml");
//webapp.marshal(out);
Marshaller mars = new Marshaller(out);
mars.setMapping(mapping);
mars.marshal(webapp);
out.close();
} catch (Exception e) {
System.out.println(e);
}
}
public static void printWebXML(WebApp webapp) {
. . .
|
When we run the program we discover two shortcomings in webapp.xml:
a. The type-attribute in the field element is "int", and must be
replaced by "integer"
b. The field "loadOnStartup" must have node-value "element"
instead of "attribute".
With these changes we'll get the correct format of the output file. If you don't want the use of namespaces in the file you should simply remove the namespaces in webapp.xml. Here's a modified webapp.xml file .
If you have read my articles about Castor JDO you may have noticed how its mapping files resemble Castor XML's mapping files. Where Castor XML for examples uses this format:
. . .
<class name="demo.Person">
<map-to xml="person"/>
<field name="occupation" type="string">
<bind-xml name="occupation" node="attribute"/>
</field>
<field name="lastName" type="string">
<bind-xml name="lastname" node="element"/>
</field>
</class>
. . .
|
then Castor JDO will use this format:
. . .
<class name="demo.Person">
<map-to table="person"/>
<field name="occupation" type="string">
<sql name="occupation" type="string"/>
</field>
<field name="lastName" type="string">
<sql name="lastname" node="string"/>
</field>
</class>
. . .
|
It's possible to combine the two formats in one mapping file, and with this you could read an XML-file to get Java objects, and then write them to a relational data base--and back again!
To setup the mapping file for the web.xml example to use JDO, you'd also need to make some additions mainly pertaining to the one-to-many relations, but it's beyond the scope of this article to go into all the details. Maybe it's a topic for a new article?
If you're working with XML documents, and your focus is more on the contents of the documents, and not so much on the XML structure, then Castor XML is a good choice. Castor has several tools that'll help you get your XML data converted to Java objects. If you've already coded your Java classes, then define a mapping file that shows Castor how to do the conversion. If you're starting from the XML side, then you'll need an XML Schema or a DTD that defines your XML documents, and Castor may then build your Java classes. An example XML document may also be used to get started, but be prepared to do some adjustments to the generated Schema.
Castor is not the only Data Binding framework around. A significant competitor is the Java API for XML Binding (JAXB). If you're interested in more information on Data Binding I'd recommend the intro in the resources section that follows.
To learn more about Castor XML it's a good idea to start reading the short, but useful documentation found on the Castor web site. It's also part of the Castor download. It's easy to overlook, but use the menu to the left on the home page to see the various topics covered.
;){kind=link}